FastSAM for image segmentation
2025/09/19
Architecture
The inference process in FastSAM consists of two stages:
- Segmentation of all objects. The goal is to create segmentation masks for all objects in the image.
- Hinted Select. After receiving all possible masks, the Hinted Select function returns the area of the image corresponding to the entered hint.
“The FastSAM architecture is based on YOLOv8-seg, an object detector equipped with an instance segmentation branch that uses the YOLACT method” - Fast Segment Anything article
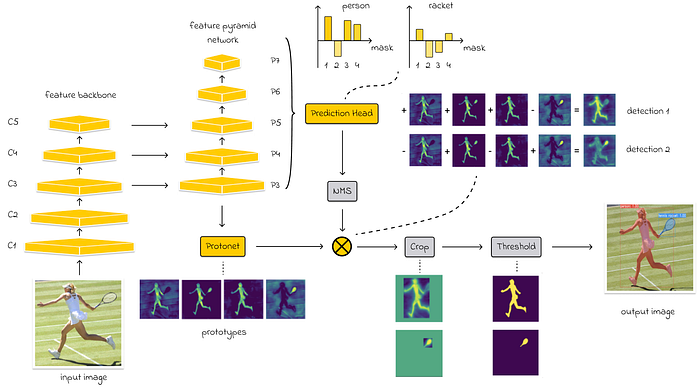
YOLACT (You Only Look at CoefficienTs) - “You only look at the coefficients”
YOLACT is a real-time convolutional object segmentation model targeting high-speed detection. It is based on the YOLO model and is comparable in performance to the Mask R-CNN model.
YOLACT consists of two main modules (branches):
- Prototype branch. YOLACT creates a set of segmentation masks called prototypes.
- Prediction Branch YOLACT performs object detection by predicting bounding boxes and then estimates camouflage coefficients, which tell the model how to linearly combine prototypes to create the final camouflage for each object.
YOLACT architecture: yellow blocks indicate trainable parameters, and gray blocks indicate untrainable parameters. Source: YOLACT, Real-Time Object Segmentation. The number of mask prototypes in the image is k = 4.
To extract raw features from an image, YOLACT uses ResNet and then Feature Pyramid Network (FPN) to extract features at different scales. Each of the P-layers (shown in the image) processes features of different sizes using convolutional operations (for example, P3 contains the smallest features, and P7 contains higher-level image features). This approach helps YOLACT take into account objects of different sizes.
YOLOv8-seg
YOLOv8-seg is a model based on YOLACT and uses the same principles for prototypes. It also consists of two blocks:
- Detection block. Used to predict bounding boxes and classes.
- Segmentation Header. Used to create masks and combine them.
The key difference is that YOLOv8-seg uses the underlying YOLO architecture instead of the underlying ResNet and FPN architecture used in YOLACT. Thanks to this, YOLOv8-seg is faster and requires fewer resources when outputting data.
FastSAM architecture
The FastSAM architecture is based on YOLOv8-seg, but also includes FPN as in YOLACT. It includes detection and segmentation modules with k = 32 prototypes. However, since FastSAM performs segmentation of all possible objects in the image, its workflow differs from the YOLOv8-seg and YOLACT processes:
- FastSAM first performs segmentation, creating k = 32 image masks.
- These masks are then combined to obtain the final segmentation mask.
- During post-processing, FastSAM extracts regions, computes bounding boxes, and performs instance segmentation for each object.

FastSAM architecture: yellow blocks indicate trainable parameters, and gray blocks indicate untrainable parameters. Source: Fast Segment Anything
Training
The FastSAM researchers used the same SA-1B dataset as the SAM developers, but trained the CNN detector on only 2% of the data. Despite this, the CNN detector achieves comparable performance to the original SAM while requiring significantly fewer resources for segmentation. As a result, FastSAM works 50 times faster!
Why is FastSAM faster than SAM? SAM uses the Vision Transformer (ViT) architecture, which is known for its high compute requirements. Unlike SAM, FastSAM performs segmentation using convolutional neural networks, which are much lighter.
Point hint
After obtaining several image prototypes, we can use a point hint to indicate that an object of interest is (or is not) located in a certain area of the image. Thus, the specified point affects the coefficients for the prototype masks.
Like SAM, FastSAM allows you to select multiple points and specify whether they are foreground or background. If the foreground point corresponding to an object is present in multiple masks, you can use the background points to filter out unnecessary masks.
However, if after filtering multiple masks still match the specified parameters, mask merging is applied to obtain the final mask for the object.
In addition, the authors use morphological operators to smooth the final mask shape and remove small artifacts and noise.
Hint from the box
The box request involves selecting the mask whose bounding box has the greatest intersection over Union (IoU) with the bounding box specified in the request.
Text hint
Similarly, for a text query, the mask that best matches the text description is selected. To do this, use the CLIP model:
FastSAM Repository
Below is a link to the official FastSAM repository which has a clear README.md file and documentation.
https://arxiv.org/pdf/2306.12156