FastSAM для сегментации изображений
2025/09/19
Архитектура
Процесс логического вывода в FastSAM состоит из двух этапов:
- Сегментация всех объектов. Цель состоит в том, чтобы создать маски сегментации для всех объектов на изображении.
- Выбор с подсказкой. После получения всех возможных масок функция выбора с подсказкой возвращает область изображения, соответствующую введенной подсказке.
«Архитектура FastSAM основана на YOLOv8-seg — детекторе объектов, оснащённом веткой сегментации экземпляров, в которой используется метод YOLACT» — статья Fast Segment Anything
YOLACT (You Only Look at CoefficienTs) — «Ты смотришь только на коэффициенты»
YOLACT — это свёрточная модель сегментации объектов в реальном времени, ориентированная на высокоскоростное обнаружение. Она создана на основе модели YOLO и по производительности сравнима с моделью Mask R-CNN.
YOLACT состоит из двух основных модулей (ветвей):
- Ветка прототипов. YOLACT создает набор масок сегментации, называемых прототипами.
- Ветвь прогнозирования. YOLACT выполняет обнаружение объектов, прогнозируя ограничительные рамки, а затем оценивает коэффициенты маскировки, которые указывают модели, как линейно комбинировать прототипы для создания окончательной маскировки для каждого объекта.
Архитектура YOLACT: жёлтые блоки обозначают обучаемые параметры, а серые — необучаемые. Источник: YOLACT, сегментация объектов в реальном времени. Количество прототипов масок на изображении — k = 4.
Для извлечения исходных признаков из изображения YOLACT использует ResNet, а затем сеть Feature Pyramid Network (FPN) для получения признаков в разных масштабах. Каждый из P-уровней (показан на изображении) обрабатывает признаки разного размера с помощью свёрточных операций (например, P3 содержит самые мелкие признаки, а P7 — признаки изображения более высокого уровня). Такой подход помогает YOLACT учитывать объекты разных размеров.
YOLOv8-seg
YOLOv8-seg — это модель, основанная на YOLACT и использующая те же принципы в отношении прототипов. Она также состоит из двух блоков:
- Блок обнаружения. Используется для прогнозирования ограничивающих рамок и классов.
- Заголовок сегментации. Используется для создания масок и их объединения.
Ключевое отличие заключается в том, что YOLOv8-seg использует базовую архитектуру YOLO вместо базовой архитектуры ResNet и FPN, используемых в YOLACT. Благодаря этому YOLOv8-seg работает быстрее и требует меньше ресурсов при выводе данных.
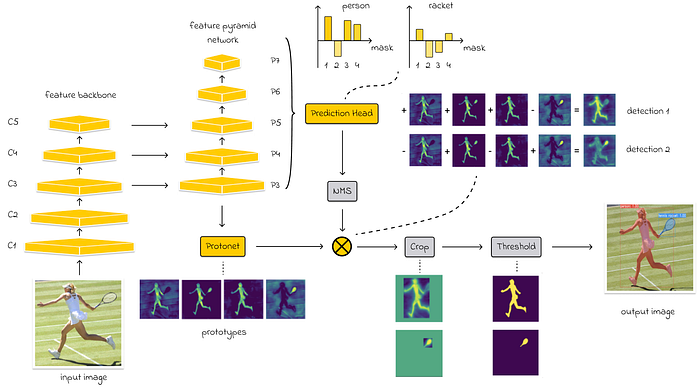
Архитектура FastSAM
Архитектура FastSAM основана на YOLOv8-seg, но также включает в себя FPN, как в YOLACT. Она включает в себя модули обнаружения и сегментации с k = 32 прототипами. Однако, поскольку FastSAM выполняет сегментацию всех возможных объектов на изображении, его рабочий процесс отличается от процессов YOLOv8-seg и YOLACT:
- Сначала FastSAM выполняет сегментацию, создавая k = 32 масок изображений.
- Затем эти маски объединяются для получения окончательной маски сегментации.
- Во время постобработки FastSAM выделяет области, вычисляет ограничивающие рамки и выполняет сегментацию экземпляров для каждого объекта.

Архитектура FastSAM: жёлтые блоки обозначают обучаемые параметры, а серые — необучаемые. Источник: Fast Segment Anything
Обучение
Исследователи FastSAM использовали тот же набор данных SA-1B, что и разработчики SAM, но обучали детектор CNN только на 2 % данных. Несмотря на это, детектор CNN обеспечивает производительность, сопоставимую с оригинальным SAM, при этом для сегментации требуется значительно меньше ресурсов. В результате FastSAM работает в 50 раз быстрее!
Почему FastSAM работает быстрее, чем SAM? В SAM используется архитектура Vision Transformer (ViT), которая известна своими высокими требованиями к вычислительным ресурсам. В отличие от SAM, FastSAM выполняет сегментацию с помощью свёрточных нейронных сетей, которые гораздо легче.
Подсказка точки
После получения нескольких прототипов изображения можно использовать точечную подсказку, чтобы указать, что интересующий нас объект находится (или не находится) в определённой области изображения. Таким образом, указанная точка влияет на коэффициенты для масок прототипов.
Как и SAM, FastSAM позволяет выбирать несколько точек и указывать, относятся ли они к переднему плану или фону. Если точка переднего плана, соответствующая объекту, присутствует в нескольких масках, можно использовать точки фона для фильтрации ненужных масок.
Однако, если после фильтрации несколько масок по-прежнему соответствуют заданным параметрам, применяется объединение масок для получения окончательной маски для объекта.
Кроме того, авторы применяют морфологические операторы для сглаживания окончательной формы маски и удаления мелких артефактов и шумов.
Подсказка из коробки
Запрос box включает в себя выбор маски, ограничивающий прямоугольник которой имеет наибольшее пересечение над Union (IoU) с ограничивающим прямоугольником, указанным в запросе.
Текстовая подсказка
Аналогичным образом для текстового запроса выбирается маска, которая лучше всего соответствует текстовому описанию. Для этого используется модель CLIP:
Репозиторий FastSAM
Ниже приведена ссылка на официальный репозиторий FastSAM, в котором есть понятный файл README.md и документация.
https://arxiv.org/pdf/2306.12156